
flowchart LR
A[Hard edge] --> B(Round edge)
B --> C{Decision}
C --> D[Result one]
C --> E[Result two]
There are many challenges in talking about the mitigation of (and adaptation to) potentially disastrous climate events when their probability and timing is poorly constrained. Here, I focus primarily on fundamental confusions about probability and how to use it in decision making. Many of these reflections are based on my experience as a university teacher and public speaker.
Probability isn’t intuitive
Everyday uncertainty
Probability is a mathematical measure for uncertainty. That sounds simple enough, but if you aren’t a mathematician (perhaps even if you are), browsing a list of mathematical measures will soon have you scratching your head. Most other measures will seem rather abstract.
So why do many of us feel that we have a good intuitive grasp on probability?
A quick word search on Google Books Ngram Viewer, a tool that lets you plot the frequency of the yearly count of words (or n-grams to be specific) found in Google’s text corpora, can give us an idea of how often probability-themed words are used. Here, we’re comparing “probability”, “chance”, and “likely” to common words like “goodbye”, “bird”, and “woman”.
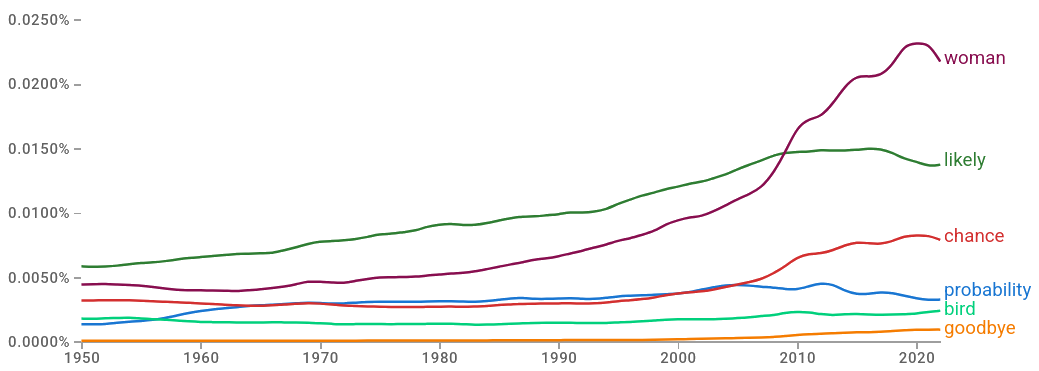
This is no accurate representation of our daily conversations and thoughts, of course, but it is a good-enough measure to demonstrate how prevalent this concept of probability and uncertainty generally is. This is no surprise, given that every observation we make is incomplete and, consequently, comes with uncertainty. Therefore, every decision based on these incomplete observations is a decision made under uncertainty. A sense – or measure – of this uncertainty allows us to deal with it more confidently. Perhaps our daily use of some interpretation of probability gives us confidence in our intuitive grasp of the mathematical concept. Perhaps it comes from somewhere else. Regardless, it is often a wild overestimation of our ability to understand probability.
A game of dice
Probability isn’t intuitive – this is a point I always make at the beginning of my series of lectures on statistics and probability theory. A few years ago, I invested in a (supposedly) perfectly balanced and fair d20 – that’s a 20 sided die (for those of you who haven’t played classic pen-and-paper role-playing games). I sometimes roll it and record the outcomes, because it relaxes me. I have no life, I know – but at least I have a cool dataset!
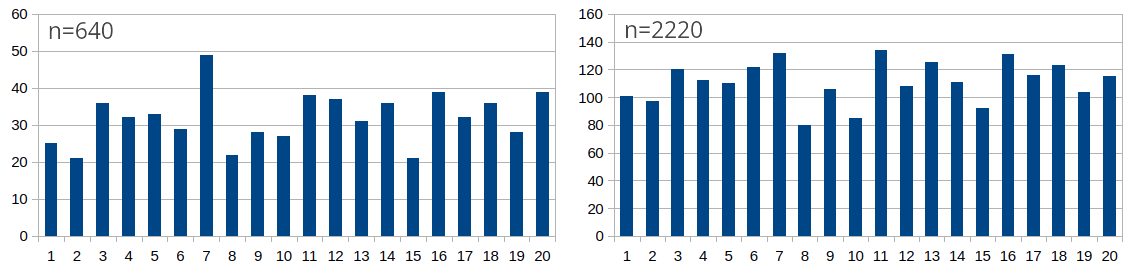
I use the dataset for a little game: I show the outcomes after n rolls to my students in increments – the outcomes after a hundred rolls, a few hundred rolls, a thousand rolls, a few thousand rolls. After each presentation of the outcomes, I ask my students if they (still) believe the d20 is fair. When crossing the n=640 mark and the number 7 still has the lead (was rolled most often), several students start believing in a bias. Typically, only those with a background in mathematics and statistics continue to insist that we can’t confidently call this a bias yet. (I wonder if the blog post will change this. probably not; I doubt there’s an interest in reading your professor’s blog posts). Indeed, 7’s lead starts to disappear in later experiments, as it gets “diluted” by the new outcomes and is no longer conspicuous at n=2220.
Let’s have a quick look at the statistics of it. If that doesn’t sound appealing, you can just skip this part. (If you are a student of mine, you better check it! 😏 )
NoteIs our d20 fair?
insert equations and fortran code
! chi-squared testI wrote that 7’s lead gets “diluted” to stress that the probability of rolling a 7 in later experiments is not impacted by having rolled it more than the other numbers in earlier experiments. The ~equal number of rolls of each number on a fair die is not achieved by changes in the probability of rolling non-7’s to somehow make up for the difference. Instead, 7’s earlier lead is simply “diluted” by new, more balanced outcomes as n increases. For some reason, the first (false) explanation is often favoured by students (and non-students) before they are exposed to theory. Maybe it reflects our desire for a universe (or something) that intervenes with intention, because anything else would overwhelm us and fill us with existential dread? (I’m sure there’s some research on this). In any case, this persistent misunderstanding is but one of many indicators that leads us to the conclusion that humans do not have a good natural understanding of probability. I could go on about the misunderstanding of large and small numbers, the unintuitiveness of the independence of events, cognitive biases, and more. Instead, I’ll simply conclude the section as I started it: Probability isn’t intuitive.
Entangling probability and cost
Probability is usually communicated with an associated event and potential gains and losses of specific outcomes. It is this event, and what that the outcomes mean to us, that makes this abstract concept of probability more tangible. However, this also means that our assessment of a probability is influenced very much by associated event outcomes.
Imagine you’re enjoying a social gathering. Consider the following premise:
If you wait here for a few more minutes, there is a 20% probability of missing the bus.
Sure, we don’t want to miss our bus, but it’s not the end of the world if we do. If it means we can socialise some more with the friends we haven’t seen in a while, missing the bus will have been worth it. Besides, 20% isn’t that high. We will probably get it anyway, even if we stay for a little longer.
Now consider the following, where we modified the outcome:
If you wait here for a few more minutes, there is a 20% probability of being hit by the bus.
[I’m not sure how this would work, but let’s just accept the premise.]
The probability hasn’t changed, but our perception and assessment of it has, because now there’s a risk of serious injury or death. Suddenly, 20% is unreasonably high. That’s a higher probability than rolling a 6 on a 6-sided die!
Our understanding of probability is entagled with the associated event and its outcomes. The potential gains or losses of an outcome makes it seem less abstract and more understandable, and we assess the probability by these outcomes. What complicates this further is that costs always have a subjective component. Consider a 50% probability of losing 100€. Even if we can quantify costs as a monetary loss of 100€, these 100€ will be negligible to some and unbearably high to others, depending on their financial situation. Consequently, this will create vastly different perceptions or assessments of the probability associated with this loss. For some, 50% will be acceptable. For others, 50% will be very high.
Where does that leave us with communication of probabilities and associated events in general?
It’s unreasonable to expect to achieve widespread statistical literacy, so I don’t share some of my colleagues’ opinions that this is the solution – not that I would mind if it did happen. So if that’s not an option, how do we learn to effectively communicate probability and cost as a package? How do we account for subjective factors? How do we make costs tangible when most have not yet experienced what is to come?